
Java编码问题解决方案大揭密
本文为原创,如需转载,请注明作者和出处,谢谢!<!-- [if gte mso 9]><xml> Normal 0 7.8 磅 0 2 false false false MicrosoftInternetExplorer4 </xml><![endif]--><!-- [if gte mso 9]><![endif]--> <!-- /* Font Definitions */ @font-face {font-family:Batang; panose-1:2 3 6 0 0 1 1 1 1 1;} @font-face {font-family:宋体; panose-1:2 1 6 0 3 1 1 1 1 1;} @font-face {font-family:""@宋体"; panose-1:2 1 6 0 3 1 1 1 1 1;} @font-face {font-family:""@Batang"; panose-1:2 3 6 0 0 1 1 1 1 1;} /* Style Definitions */ p.MsoNormal, li.MsoNormal, div.MsoNormal {mso-style-parent:""; margin:0cm; margin-bottom:.0001pt; text-align:justify; text-justify:inter-ideograph; font-size:10.5pt; font-family:"Times New Roman";} /* Page Definitions */ @page {} @page Section1 {size:612.0pt 792.0pt; margin:72.0pt 90.0pt 72.0pt 90.0pt;} div.Section1 {page:Section1;} --> <!-- [if gte mso 10]> <style> /* Style Definitions */ table.MsoNormalTable { mso-style-parent:""; font-size:10.0pt; font-family:"Times New Roman"; mso-fareast-font-family:"Times New Roman";} </style> <![endif]-->
一、 Java 编码是怎么回事?
对于使用中文以及其他非拉丁语系语言的开发人员来说,经常会遇到字符集编码问题。对于 Java语言来说,在其内部使用的是 UCS2编码( 2个字节的 Unicode编码)。这种编码并不属于某个语系的语言编码,它实际上是一种编码格式的世界语。在这个世界上所有可以在计算机中使用的语言都有对应的 UCS2编码。
正是因为 Java采用了 UCS2,因此,在 Java中可以使用世界上任何国家的语言来为变量名、方法名、类起名,如下面代码如下:
{
public String 雄起()
{
return " 中国雄起 " ;
}
}
中国 祖国 = new 中国();
System.out.println(祖国.雄起());
哈哈,是不是有点象“中文编程”。实际上,也可以使用其他的语言来编程,如下面用韩文和日文来定义个类:
{
public void スーパーマン() {
 }
}}
实际上,由于 Java内部使用的是 UCS2编码格式,因为, Java并不关心所使用的是哪种语言,而只要这种语言在 UCS2中有定义就可以。
在 UCS2编码中为不同国家的语言进行了分页,这个分页也叫“代码页”或“编码页”。中文根据包含中文字符的多少,分了很多代码页,如 cp935、 cp936等,然而,这些都是在 UCS2中的代码页名,而对于操作系统来说,如微软的 windows,一开始的中文编码为 GB2312,后来扩展成了 GBK。其实 GBK和 cp936是完全等效的,用它们哪个都行。
二、
Java
编码转换
上面说了这么多,在这一部分我们做一些编码转换,看看会发生什么事情。
先定义一个字符串变量:
String gbk = "
中国
"; // “中国”在
Java内部是以
UCS2格式保存的
用下面的语言输出一定会输出中文:
System.out.println(gbk);
实现上,当我们从
IDE输入“中国”时,用的是
java源代码文件保存的格式,一般是
GBK,有时也可是
utf-8,而在
Java编译程序时,会不由分说地将所有的编码格式转换成
utf-8编码,读者可以用
UltraEdit或其他的二进制编辑器打开上面的“中国
.class”,看看所生成的二进制是否有
utf-8的编码(
utf-8和
ucs2之间的转换非常容易,因为
utf-8和
ucs2之间是用公式进行转换的,而不是到代码页去查,这就相当于将二进制转成
16进制一样,
4个字节一组)。如“中国”的
utf-8编码按着
GBK解析就是“涓
浗
”。如下图所示。
<!-- [if gte mso 9]><xml>
Normal
0
7.8 磅
0
2
false
false
false
MicrosoftInternetExplorer4
</xml><![endif]--><!-- [if gte mso 9]><![endif]-->
<!--
/* Font Definitions */
@font-face
{font-family:Batang;
panose-1:2 3 6 0 0 1 1 1 1 1;}
@font-face
{font-family:宋体;
panose-1:2 1 6 0 3 1 1 1 1 1;}
@font-face
{font-family:""@宋体";
panose-1:2 1 6 0 3 1 1 1 1 1;}
@font-face
{font-family:""@Batang";
panose-1:2 3 6 0 0 1 1 1 1 1;}
/* Style Definitions */
p.MsoNormal, li.MsoNormal, div.MsoNormal
{mso-style-parent:"";
margin:0cm;
margin-bottom:.0001pt;
text-align:justify;
text-justify:inter-ideograph;
font-size:10.5pt;
font-family:"Times New Roman";}
/* Page Definitions */
@page
{}
@page Section1
{size:612.0pt 792.0pt;
margin:72.0pt 90.0pt 72.0pt 90.0pt;}
div.Section1
{page:Section1;}
-->
<!-- [if gte mso 10]>
<style>
/* Style Definitions */
table.MsoNormalTable
{
mso-style-parent:"";
font-size:10.0pt;
font-family:"Times New Roman";
mso-fareast-font-family:"Times New Roman";}
</style>
<![endif]-->
如果使用下面的语言可以获得“中国”的 utf-8字节,结果是 6(一个汉字由 3个字节组成)
System.out.println(gbk.getBytes("utf-8").length);
下面的代码将输出“涓 浗 ”。
System.out.println(new String(gbk.getBytes("utf-8"), "gbk"));
由于将“中国“的 utf-8编码格式按着 gbk解析,所以会出现乱码。
如果要返回中文的 UCS2编码,可以使用下面的代码:
System.out.println(gbk.getBytes("unicode")[2]);
System.out.println(gbk.getBytes("unicode")[3]);
前两个字节是标识位,要从第
3个字节开始。还有就是其他的语言使用的编码的字节顺序可能不同,如在
C#中可以使用下面的代码获得“中国“的
UCS2编码:
String s = "
中
";
MessageBox.Show(ASCIIEncoding.Unicode.GetBytes(s)[0].ToString());
MessageBox.Show(ASCIIEncoding.Unicode.GetBytes(s)[1].ToString());
使用上面的 java代码获得的“中“的 16进制 UCS2编码为 4E2D,而使用 C#获得的相应的 ucs2编码为 2D4E,这只是 C#和 Java编码内部使用的问题,并没有什么关系。但在 C#和 Java互操作时要注意这一点。
如果使用下面的 java编码将获得 16进制的“中”的 GBK编码:
System.out.println(Integer.toHexString(0xff & xyz.getBytes("gbk")[0]));
System.out.println(Integer.toHexString(0xff & xyz.getBytes("gbk")[1]));
“中”的 ucs2编码为 2D4E, GBK编码为 D6D0
读者可访问如下的
url自行查验:
http://unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP936.TXT
当然,感兴趣的读者也可以试试其他语言的编码,如“人类”的韩语是“ 인간의 ”,如下面的代码将输出“ 인간의 ”的 cp949和 ucs2编码,其中 cp949是韩语的代码页。
System.out.println(Integer.toHexString( 0xff & korean.getBytes( " unicode " )[ 2 ]));
System.out.println(Integer.toHexString( 0xff & korean.getBytes( " unicode " )[ 3 ]));
System.out.println(Integer.toHexString( 0xff & korean.getBytes( " Cp949 " )[ 0 ]));
System.out.println(Integer.toHexString( 0xff & korean.getBytes( " Cp949 " )[ 1 ]));
上面代码的输出结果如下:
<!-- [if gte mso 9]><xml> Normal 0 7.8 磅 0 2 false false false MicrosoftInternetExplorer4 </xml><![endif]--><!-- [if gte mso 9]><![endif]--> <!-- /* Font Definitions */ @font-face {font-family:Batang; panose-1:2 3 6 0 0 1 1 1 1 1;} @font-face {font-family:宋体; panose-1:2 1 6 0 3 1 1 1 1 1;} @font-face {font-family:""@宋体"; panose-1:2 1 6 0 3 1 1 1 1 1;} @font-face {font-family:""@Batang"; panose-1:2 3 6 0 0 1 1 1 1 1;} /* Style Definitions */ p.MsoNormal, li.MsoNormal, div.MsoNormal {mso-style-parent:""; margin:0cm; margin-bottom:.0001pt; text-align:justify; text-justify:inter-ideograph; font-size:10.5pt; font-family:"Times New Roman";} /* Page Definitions */ @page {} @page Section1 {size:612.0pt 792.0pt; margin:72.0pt 90.0pt 72.0pt 90.0pt;} div.Section1 {page:Section1;} --> <!-- [if gte mso 10]> <style> /* Style Definitions */ table.MsoNormalTable { mso-style-parent:""; font-size:10.0pt; font-family:"Times New Roman"; mso-fareast-font-family:"Times New Roman";} </style> <![endif]-->c7
78
c0
ce
也就是说“
인
”的
ucs2
编码为
C778
,
cp949
的编码为
C0CE
,要注意的是,在
cp949
中,
ucs2
编码也有
C0CE
,不要弄混了。读者可以访问下面的
url
来验证:
http://unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/CP949.TXT
<!-- [if gte mso 9]><xml>
Normal
0
7.8 磅
0
2
false
false
false
MicrosoftInternetExplorer4
</xml><![endif]--><!-- [if gte mso 9]><![endif]--><!-- [if !mso]>
<style>
st1":*{behavior:url(#ieooui) }
</style>
<![endif]-->
<!--
/* Font Definitions */
@font-face
{font-family:宋体;
panose-1:2 1 6 0 3 1 1 1 1 1;}
@font-face
{font-family:""@宋体";
panose-1:2 1 6 0 3 1 1 1 1 1;}
/* Style Definitions */
p.MsoNormal, li.MsoNormal, div.MsoNormal
{mso-style-parent:"";
margin:0cm;
margin-bottom:.0001pt;
text-align:justify;
text-justify:inter-ideograph;
font-size:10.5pt;
font-family:"Times New Roman";}
/* Page Definitions */
@page
{}
@page Section1
{size:612.0pt 792.0pt;
margin:72.0pt 90.0pt 72.0pt 90.0pt;}
div.Section1
{page:Section1;}
-->
Java支持的编码格式
三、属性文件
Java中的属性文件只支持 iso-8859-1编码格式,因此,要想在属性文件中保存中文,就必须使用 UCS2编码格式( "uxxxx),因此,出现了很多将这种编码转换成可视编码和工具,如 Eclipse中的一些属性文件编辑插件。
实际上,
"uxxxx编码格式在
java和
C#中都可以使用,如下面的语句所示:
String name= ""u7528"u6237"u540d"u4e0d"u80fd"u4e3a"u7a7a"
;
System.out.println(name);
上面代码将输出“用户名不能为空”的信息。将 "uxxxx 格式显示成中文非常简单,那么如何将中文还原成 "uxxxxx 格式呢?下面的代码完成了这个工作:<!-- [if gte mso 9]><xml> Normal 0 7.8 磅 0 2 false false false MicrosoftInternetExplorer4 </xml><![endif]--><!-- [if gte mso 9]><![endif]--><!-- [if !mso]> <style> st1":*{behavior:url(#ieooui) } </style> <![endif]--> <!-- /* Font Definitions */ @font-face {font-family:宋体; panose-1:2 1 6 0 3 1 1 1 1 1;} @font-face {font-family:""@宋体"; panose-1:2 1 6 0 3 1 1 1 1 1;} /* Style Definitions */ p.MsoNormal, li.MsoNormal, div.MsoNormal {mso-style-parent:""; margin:0cm; margin-bottom:.0001pt; text-align:justify; text-justify:inter-ideograph; font-size:10.5pt; font-family:"Times New Roman";} /* Page Definitions */ @page {} @page Section1 {size:612.0pt 792.0pt; margin:72.0pt 90.0pt 72.0pt 90.0pt;} div.Section1 {page:Section1;} -->
byte [] uncode = ss.getBytes( " Unicode " );
int x = 0xff ;
String result = "" ;
for ( int i = 2 ; i < uncode.length; i ++ )
{
if (i % 2 == 0 ) result += " \\u " ;
String abc = Integer.toHexString(x & uncode[i]);
result += abc.format( " %2s " , abc).replaceAll( " " , " 0 " );
}
System.out.println(result);
<!-- [if gte mso 9]><xml> Normal 0 7.8 磅 0 2 false false false MicrosoftInternetExplorer4 </xml><![endif]--><!-- [if gte mso 9]><![endif]--><!-- [if !mso]> <style> st1":*{behavior:url(#ieooui) } </style> <![endif]--> <!-- /* Font Definitions */ @font-face {font-family:宋体; panose-1:2 1 6 0 3 1 1 1 1 1;} @font-face {font-family:""@宋体"; panose-1:2 1 6 0 3 1 1 1 1 1;} /* Style Definitions */ p.MsoNormal, li.MsoNormal, div.MsoNormal {mso-style-parent:""; margin:0cm; margin-bottom:.0001pt; text-align:justify; text-justify:inter-ideograph; font-size:10.5pt; font-family:"Times New Roman";} /* Page Definitions */ @page {} @page Section1 {size:612.0pt 792.0pt; margin:72.0pt 90.0pt 72.0pt 90.0pt;} div.Section1 {page:Section1;} --> <!-- [if gte mso 10]> <style> /* Style Definitions */ table.MsoNormalTable { mso-style-parent:""; font-size:10.0pt; font-family:"Times New Roman"; mso-fareast-font-family:"Times New Roman";} </style> <![endif]--> 上面的代码将输出如下结果:
\u7528\u6237\u540d\u4e0d\u80fd\u4e3a\u7a7a
好了,现在可以利用这个技术来实现一个属性文件编辑器了。
四、 Web 中的编码问题
大家碰到最多的编码问题就是在 Web 应用中。先让我们看看下面的程序:
<% @ page language = " java " pageEncoding = " utf-8 " %>
< html >
< head >
</ head >
< body >
< form action ="servlet/MyPost" method ="post" >
< input type ="text" name ="user" />
< p />
< input type ="submit" value ="提交" />
</ form >
</ body >
</ html >
<!-- [if gte mso 9]><xml>
Normal
0
7.8 磅
0
2
false
false
false
MicrosoftInternetExplorer4
</xml><![endif]--><!-- [if gte mso 9]><![endif]-->
<!--
/* Font Definitions */
@font-face
{font-family:宋体;
panose-1:2 1 6 0 3 1 1 1 1 1;}
@font-face
{font-family:""@宋体";
panose-1:2 1 6 0 3 1 1 1 1 1;}
/* Style Definitions */
p.MsoNormal, li.MsoNormal, div.MsoNormal
{mso-style-parent:"";
margin:0cm;
margin-bottom:.0001pt;
text-align:justify;
text-justify:inter-ideograph;
font-size:10.5pt;
font-family:"Times New Roman";}
/* Page Definitions */
@page
{}
@page Section1
{size:612.0pt 792.0pt;
margin:72.0pt 90.0pt 72.0pt 90.0pt;}
div.Section1
{page:Section1;}
-->
<!-- [if gte mso 10]>
<style>
/* Style Definitions */
table.MsoNormalTable
{
mso-style-parent:"";
font-size:10.0pt;
font-family:"Times New Roman";
mso-fareast-font-family:"Times New Roman";}
</style>
<![endif]-->
下面是个
Servlet
:
import java.io.IOException;
import java.io.PrintWriter;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
public class MyPost extends HttpServlet
{
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
String user = request.getParameter( " user " );
System. out .println(user);
}
}
<!-- [if gte mso 9]><xml>
Normal
0
7.8 磅
0
2
false
false
false
MicrosoftInternetExplorer4
</xml><![endif]--><!-- [if gte mso 9]><![endif]--><!-- [if !mso]>
<style>
st1":*{behavior:url(#ieooui) }
</style>
<![endif]-->
<!--
/* Font Definitions */
@font-face
{font-family:宋体;
panose-1:2 1 6 0 3 1 1 1 1 1;}
@font-face
{font-family:""@宋体";
panose-1:2 1 6 0 3 1 1 1 1 1;}
/* Style Definitions */
p.MsoNormal, li.MsoNormal, div.MsoNormal
{mso-style-parent:"";
margin:0cm;
margin-bottom:.0001pt;
text-align:justify;
text-justify:inter-ideograph;
font-size:10.5pt;
font-family:"Times New Roman";}
/* Page Definitions */
@page
{}
@page Section1
{size:612.0pt 792.0pt;
margin:72.0pt 90.0pt 72.0pt 90.0pt;}
div.Section1
{page:Section1;}
-->
<!-- [if gte mso 10]>
<style>
/* Style Definitions */
table.MsoNormalTable
{
mso-style-parent:"";
font-size:10.0pt;
font-family:"Times New Roman";
mso-fareast-font-family:"Times New Roman";}
</style>
<![endif]-->
如果中
main.jsp中输入中文后,向
MyPost提交,在控制台中会输出“
ä¸
å½”,一看就是乱码。如果将
IE的当前编码设成其他的,如由
utf-8改为
gbk,仍然会出现乱码,只是乱得不一样而已。这是因为客户端提交数据时是根据浏览器当前的编码格式来提交的,如浏览器当前为
gbk编码,就以
gbk编码格式来提交。
这本身是不会出现乱码的,问题就出在
Web服务器接收数据的时候,
HttpServletRequest在将客户端传来的数据转成
ucs2码上出了问题。在默认情况下,是按着
iso-8859-1
编码格式来转的,而这种编码格式并不支持中文,所以也就无法正常显示中文了,解决这个问题的方法是用和客户端浏览器当前编码格式一致的编码来转换,如果是
utf-8,则在
doPost方法中应该用以下的语句来处理:
request.setCharacterEncoding("utf-8");
为了对每一个 Servlet都起作用,可以将上面的语句加到 filter里。
另外,我们一般使用象 MyEclipse 一样的 IDE 来编写 jsp 文件,这样的工具会根据 pageEncoding 属性将 jsp 文件保存成相应的编码格式,但如果要使用象记事本一样的简单的编辑器来编写 jsp 文件,如果 pageEncoding 是 utf-8 ,而在默认时,记事本会将文件保存成 iso-8859-1 ( ascii )格式,但在 myeclipse 里,如果文件中有中文,它是不允许我们保存成不支持中文的编码格式的,但记事本并不认识 jsp ,因此,这时在 ie 中就无法正确显示出中文了。除非用记事本将其保存在 utf-8 格式。如下图: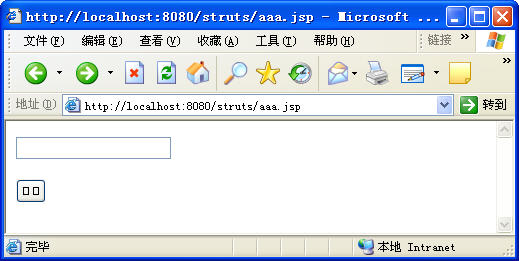
华章培训网视频教程:实现Android版的多功能日历
《Android/OPhone开发完全讲义》(本书版权已输出到台湾)
样章和目录下载
互动网 当当网 卓越亚马逊
《人人都玩开心网:Ext JS+Android+SSH整合开发Web与移动SNS》
样章下载
互动网
乐博Android手机客户端(新浪微博) 发布
<script type="text/javascript"> var _gaq = _gaq || []; _gaq.push(['_setAccount', 'UA-16915591-1']); _gaq.push(['_trackPageview']); (function() { var ga = document.createElement('script'); ga.type = 'text/javascript'; ga.async = true; ga.src = ('https:' == document.location.protocol ? 'https://ssl' : 'http://www') + '.google-analytics.com/ga.js'; var s = document.getElementsByTagName('script')[0]; s.parentNode.insertBefore(ga, s); })(); </script>
posted on 2008-07-19 13:45 银河使者 阅读(4556) 评论(16) 编辑 收藏 所属分类: java 、web 、 原创



相关推荐
此问题这是本人经过数天努力,查遍网上所有此类文章最后自己解决的。转载请务必注明出处
转载 软件说明: 许多朋友反应使用后,出现Bad Version的问题,现在跟大家说明一下,我这个版本编译器是jdk1.6的,所以你们在使用的时候也请选择jdk1.6的编译器,否则会出现bad version的问题。 其他版本: jdk1.4 ...
这里要解决的最大的问题就是要制作一个与汉字内码对应的汉字点阵库,而且还要方便单片机查找。 每个GBK码由两个字节组成,第一个字节为0X81~0XFE,第二字节分为两部分,第一部分是0X40~0X7E,第二部分是0X80~0XFE...
后来查找相关资料,得知Expat不支持gb2312编码格式,主要支持UTF-8编码格式。然而我们在程序中传递数据时,往往是用的gb2312格式文本的,于是想找出办法解决之,想到两种办法: 1、改写Expat源代码,这样效率高,但...
MS1824一款多功能视频处理器,MS1824包含12通道10位视模数转換(ADC)、TV解码器、编码器、三通道10位视频数模转换(DAC)、32位数字输入輸出信号接口及字符型0SD功能。MS1824可处理隔行和逐行模拟视频或者图形输入信号...
用FileZilla Server开FTP:看图入门 (2006-09-25 12:40:11)转载▼ 分类: 网络相关 重要更新:2007年12月,为本文改录了更直观的flash视频,请见本文最末段。 0. 关于续传和乱码的说明 问:听说FileZilla不能续传...
作者编写“压缩圣手”的目的就是为快速大批量压缩解压缩提供最佳解决方案。主要功能: ★ 压缩一个目录及全部子目录成为唯一一个ZIP文件。 ★ 把指定目录下的每个文件批量压缩成独立的ZIP文件 ★ 把指定目录下的...
脚本库能够帮助我们完成编码逻辑,实现业务功能. 使用jQuery将极大的提高编写javascript代码的效率, 让写出来的代码更加优雅, 更加健壮. 同时网络上丰富的jQuery插件也让我们的工作变成了"有了jQuery,天天喝茶水"--...
为了保证网络通信安全,该项目独创了IREL(不可逆编码标签)身份认证算法,可有效防止局域网ARP欺骗等攻击。为解决服务器负载问题,该项目提出了DRT(动态响应时间)技术,根据用户操作情况,智能动态调节被控端命令...
帮助解决网页和JS文件中的中文编码问题的小工具 慎用const关键字 装箱,拆箱以及反射 动态调用对象的属性和方法——性能和灵活性兼备的方法 消除由try/catch语句带来的warning 微软的应试题完整版(附答案) 一个...
运行IIS服务器SSI(rewrite重写)插件,可在windows的IIS服务器上通过“httpd.conf”文件或将指令“Options +Includes”以ASCII编码写入“.htaccess”格式的文件来开启SSI (Server Side Includes)。 任何路径都可以...
注: 下载后发现问题很多,所以我自己修改了一遍,剔除了代码中的大部分不合理的地方加入了控制最大弹幕数的,编码GBK测试无问题,utf-8未测试(应该是不会有问题的)。 此源码为最初版,后来还重写了记录吐槽者IP、...
程序编码 (7) 在软件开发中,下面任务不属于设计阶段的是(D) A. 数据结构设计 B. 给出系统模块结构 C. 定义模块算法 D. 定义需求并建立系统模型 (8) 数据库系统的核心是(B) A. 数据模型 B. 数据库管理系统 C. 软件...
切记不能用操作系统自带的记事本修改中文模板, 否则会改变模版编码造成主题错位(中文模版编码为:UTF-8 无BOM)。 ■ 主题自带最新图片小工具,不支持添加自定义栏目的图片,只支持采用特色图片功能添加的图片。...
3. 创建mysql 测试数据库和用户表,注意,这里采用的是 utf-8 编码 创建用户表,并插入一条测试数据 程序代码 程序代码 Create TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `userName` varchar(50) ...